 Support
Support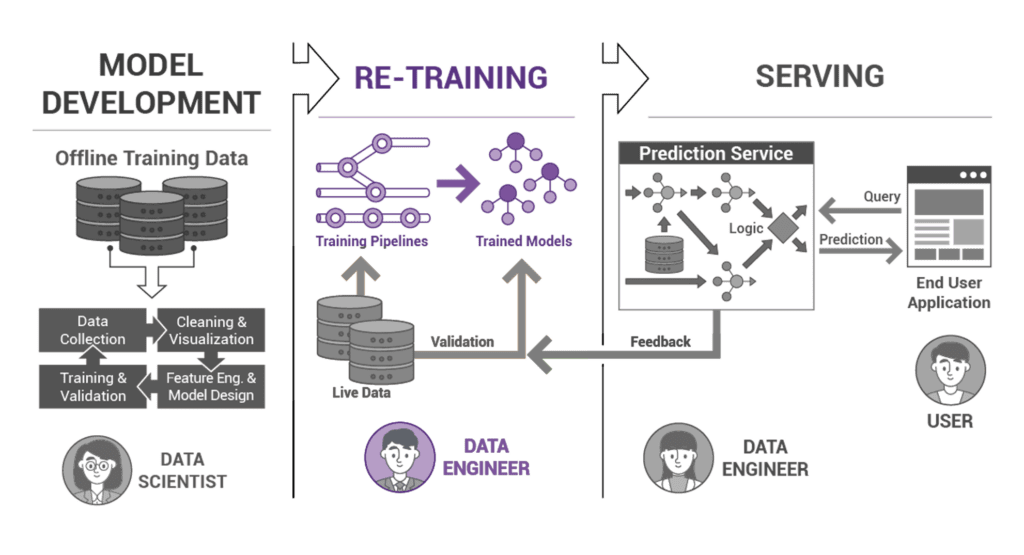
Picture this: You’ve decided to run a marathon. You’ve got the gear, you’ve plotted your route, and you’re committed. Now, it’s time to train. You start by building stamina, refining your technique, and, over time, gauging your performance to tweak and optimize your training regimen. Miss out on this crucial training phase, and come race day, you’ll find yourself gasping for air, struggling to keep up, or worse, unable to finish.
Now, imagine a machine learning system as someone preparing for that marathon. The data is the race route, while the final model is the marathon-ready version of yourself. But what about the rigorous training, the heartbeat of your preparation? That’s the “training layer” of the machine learning system.
Much like you wouldn’t just wake up one day and run a marathon without adequate preparation, a machine learning system needs its own meticulous, carefully calibrated training to make accurate predictions. And just as you continually test and adapt your training regimen based on feedback – maybe changing your diet or tweaking your running technique – the training layer of a machine learning system must also be refined and tested regularly.
If you’ve ever prepared for an important presentation, cooked a new recipe by tweaking the ingredients, or even trained for a sports event, you’ve intuitively grasped the essence of developing and testing a training layer. Today, let’s dive deeper into how this vital phase shapes the intelligence of machines.
Why a Dedicated Training Layer is Essential for a Machine Learning System
In the vast realm of machine learning, the success of a model is often judged by its ability to make precise predictions on new, unseen data. But how does a model acquire this ability? The secret lies in its training layer, the rigorous gym where raw data transforms into meaningful insights. To understand why this layer is so pivotal, let’s delve into its multifaceted roles.
The learning core for a machine learning system
Much like how athletes need regular training to keep up with ever-evolving competition standards, machine learning models, too, need consistent updates. Due to the mutable nature of data over time, model drift can occur. The training layer stands as the guardian, allowing for routine retraining, ensuring the model stays relevant. Think of a model as a rookie employee and the training layer as its supervisor. Without the supervisor, the employee wouldn’t gain knowledge. Similarly, without the training layer, a model is but an empty shell. It’s not merely about feeding data but also about fine-tuning the learning experience and adapting to the unique nuances of the data being handled. By configuring elements like learning rate or error functions, the training layer acts as the dexterous hand molding the clay, optimizing the learning process for the best possible outcome.
A testing ground for validation
The training layer acts as the model’s litmus test, consistently evaluating the model’s performance and ensuring it remains accurate and efficient. It’s akin to an artist stepping back and evaluating their artwork, making adjustments as needed. Without this introspective layer, our machine learning masterpiece might not resonate with real-world scenarios.
Facilitate the generalization of the model
A model’s real test lies in its ability to predict the unknown. The training layer prepares the model for this challenge, ensuring it doesn’t just memorize but truly understands. It’s the difference between cramming for an exam and genuinely understanding a subject. The training layer ensures our model is ready for any question, familiar or not. Without the training layer, it would be impossible to test and validate the model’s performance during development procedures, which is critical for the success of any machine learning project.
Enable the adjusting and tuning of the model
Just as professionals undergo periodic training to hone their skills, the feedback from the model’s real-world predictions is looped back into the training layer for refinements, making it an ever-evolving entity. Additionally, it provides a canvas for experimentation. Think of it as a lab where different hypotheses (models) are tested side by side to discover the most effective solution.
Support feature engineering
As our understanding deepens or as the data landscape evolves, the features (variables) our model considers might need adjustments. The training layer acts as the model’s research and development wing, continually innovating. It’s about selecting the most potent ingredients for our machine learning recipe, ensuring the end dish is both palatable and memorable. This involves selecting and transforming variables from the available dataset in order to make them better geared towards aiding the model in its learning process.
Designing, Implementing, and Testing the Training Layer for Machine Learning
The backbone of any machine learning model’s competence lies in its training layer. It is where raw data transforms, iterates, and becomes wisdom. A well-designed training layer ensures a robust and efficient model, while a hasty one can lead to disastrous results. Let’s unravel the process of building this paramount layer.
Setting clear objectives and performance metrics
Begin by crystallizing your objectives. Are you predicting house prices (regression) or identifying fraudulent transactions (classification)? Your choice sets the course. For a sailor, the North Star guides the voyage. For a data scientist, it’s the performance indicators like accuracy or RMSE that ensures the model is on the right track. Revisiting the problem statement and mapping expected outcomes help in chalking out these indicators. Once your compass is set, lay down specific requirements and standards for the training layer.
Establish data sources
A robust mechanism should be in place, ensuring that your training layer fetches clean and preprocessed data from the data layer, ready for rigorous training.
Feature engineering
Features are the essence of your model’s comprehension. Harness dynamic feature creation, making the model adaptive to evolving data landscapes.
Model selection and configuration
The beauty of machine learning lies in its diversity. Depending on the objective, you might lean towards a decision tree or a neural network. Facilitate dynamic model selection tailored to the use case. Maintain a structured ledger of your experiments. It’s vital to trace back your steps, understand decisions, and refine them. Comparative analysis tools allow a birds-eye view, making it easier to cherry-pick the best-performing model.
Dive deeper with hyperparameter tuning. Think of it as fine-tuning a musical instrument for the perfect pitch. As this process can involve hundreds or thousands of iterations, automated logging of each run’s parameters and performance metrics is crucial. With the right experiment management tools, you can quickly retrieve the best-performing hyperparameter set, saving time in later stages of deployment or retraining.
Visualization tools, often integrated within experiment management platforms, can provide insights into hyperparameter performance relationships, helping to understand and fine-tune the search space.
Training infrastructure
For mammoth datasets or intricate models, distributed training frameworks like Horovod or TensorFlow come into play. Optimize for speed by leveraging powerful hardware accelerators like GPUs or TPUs.
Balance precision and robustness
Ensure your model learns but doesn’t over-memorize. Techniques like dropout, early stopping, or L2 regularization can be the safety nets. Diversify your model’s experience through methods like data augmentation, especially in fields like image processing.
Training monitoring
Keep a vigilant eye on training metrics like loss, accuracy, etc., ensuring the model is always on the desired path. In the world of training, anomalies are your enemies. Stay alert with real-time notifications for any aberrations.
Model evaluation
Post-training, it’s time for the model to face the real world. Evaluate its prowess on a validation set. Split the data into training and validation sets. After training, evaluate the model’s performance on the validation set. For a more rigorous test, especially with limited data, k-fold cross-validation is your ally.
Versioning
Every iteration is a learning curve. Use tools like MLflow or DVC to version models after each training cycle. This allows for traceability and easy rollback if needed. Remember to ensure that you can track which version of the dataset was used for each training iteration.
Feedback loops
In a constantly evolving world, models need feedback. If available, integrate real-world prediction feedback into the training layer to refine your model.
Iterative training
With changing data landscapes, periodic retraining ensures your model remains relevant. Whenever feasible, adopt incremental training, updating the model without restarting the learning journey. A good practice involves setting up schedules (e.g., nightly, weekly) for retraining models.
Optimization and pruning
Post-training, trim the excesses. Prune your model, optimizing it for faster inference. For specific applications, consider quantizing the model, making it lightweight without compromising on efficiency.
Documentation and governance
A well-documented training process aids in reproducibility, debugging, and knowledge transfer. Document the training process, hyperparameters used, model architecture, and any other relevant details. Lastly, ensure your training layer complies with industry standards, fostering trust and adherence.