 Support
SupportThe “training ground” is a vital phase in the machine learning process known as ‘model training.’ Now, you might be wondering, “What exactly are we training and how?”
Imagine if you could teach your computer to differentiate between a cat and a dog, to recognize your handwriting, or even to predict the next big music hit. This is all possible, but first, we need to educate our machine learning models, much like how you are learning new things at school.
In the model training phase, we take a huge amount of data and let our model learn from it. It’s like giving the model a big textbook to study. The model goes through the data, learning and adapting, trying to understand the patterns and connections in the information it’s given.
The beauty here is that, through training, our models learn to make predictions and decisions on their own, getting better and better as they learn from more data. It’s like teaching a young bird to fly; initially, there are lots of falls and stumbles, but with time and practice, the bird not only learns to fly but to soar high in the sky.
The Role of Model Training in the Machine Learning Process
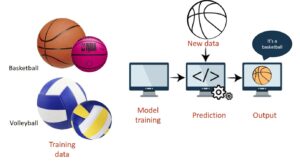
- Model Training is Where an Algorithm Learns Patterns from the Provided Data
In the model training stage, the algorithm looks at a lot of data. It learns from this data and figures out how to make good guesses. The algorithm uses math to link what it sees (inputs) to what it’s trying to predict (outputs). This helps it to make these guesses on its own.
- Model Training is the Iterative Part of the Machine Learning Process
In machine learning, the model gets better by trying many times. Each time it tries, it learns a bit more and gets better at guessing. This is important because it helps the model stay up-to-date and understand new information.
- Model Training can Involve Various Algorithms
Picking the right algorithm for training is a big decision. It depends on what problem you’re solving, what data you have, and what you want to find out. You might choose supervised learning, unsupervised learning, or reinforcement learning, depending on your needs.
- Model Training Needs to be Balanced to Avoid Overfitting or Underfitting
It’s important to train the model just right. If it learns too much from the training data, it won’t work well with new data. This is called overfitting. If it doesn’t learn enough, it won’t recognize important patterns. This is called underfitting. The goal is to train the model so it’s just right, not too much or too little.
- Model Training is Tied to Model Evaluation
Finally, after a period of rigorous training, it’s time for the ultimate test – evaluation. Here, we introduce the model to a fresh set of data (test dataset). We gauge the performance by applying various metrics such as accuracy, precision, recall, or mean squared error. This tells us if the model is ready to use or if it needs more work.
The Steps in the Model Training Stage
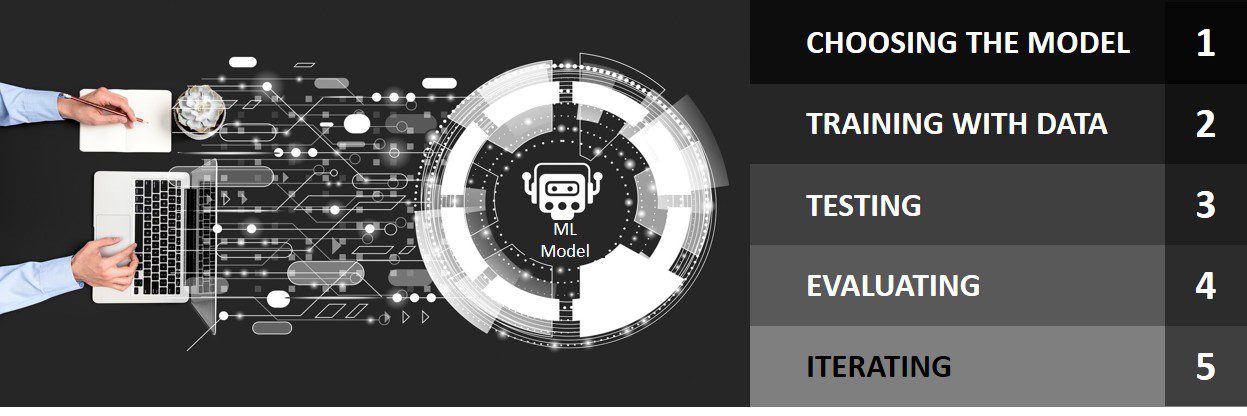
- Choosing the Appropriate Model
First, we pick the model that fits best for our task. It’s like choosing the right tool for a job. There are many types, like regression models, decision trees, and neural networks. - Training the Model with Your Data
Next, we teach the model using our data. This is where the model learns to find patterns and important bits in the data. - Testing the Model
We then test the model with new data to make sure it didn’t just memorize but can actually use what it learned in new situations. This helps to make sure the model works well in real life. - Evaluating the Model’s Performance
After testing, we look closely at how well the model did. We check how accurate its predictions are and decide if it’s ready or needs more training. - Iterating on the Model
Finally, we keep making the model better. This means training, testing, and adjusting it again and again to make sure it’s as good as it can be.
Steve’s Virtual Basketball Team
Imagine Steve is a keen player of a basketball video game. In this game, Steve can form a team of virtual players and train them to improve their skills over time. This training involves practicing different plays, improving the virtual players’ shooting accuracy, and understanding the strengths and weaknesses of the opposition.
Model training in machine learning works in a similar manner.
Like how Steve trains his virtual team based on the data of their past performances and the tactics that work best, in machine learning, we “train” our model using a large amount of data. This data can include various pieces of information that help the model learn the patterns and relationships in the data.
Just like Steve’s team getting better and better through training, our machine learning model also gets better with more training. It learns to make more accurate predictions and understand complex patterns as it is exposed to more data.
But Steve also needs to ensure his team doesn’t just become experts at beating just one opponent — they need to be versatile and ready to face any team. This is why he has practice matches against various types of opposition to ensure his strategies are robust. Similarly, we test our machine learning models on different datasets to make sure that it doesn’t just learn the patterns in the training data but can generalize well to new, unseen data, effectively predicting outcomes in a variety of situations.
So, in essence, when we talk about model training in the machine learning process, it is about using data to teach the model to make accurate predictions, just like Steve uses training to teach his virtual team to win games. This process is iterative and continuous, with the aim of developing a model that is not just good but excellent at making predictions. It is a core step in the machine learning process that leverages data to build predictive algorithms.