 Support
SupportImagine a world where machines can predict the future, make decisions, and even understand human emotions. It sounds like science fiction, right? But it’s not. It’s the magic of machine learning. Understanding the intricacies of this field can open doors to countless opportunities. Dive into the realm of machine learning and discover the best practices that ensure these machines learn effectively and the challenges they might face along the way.
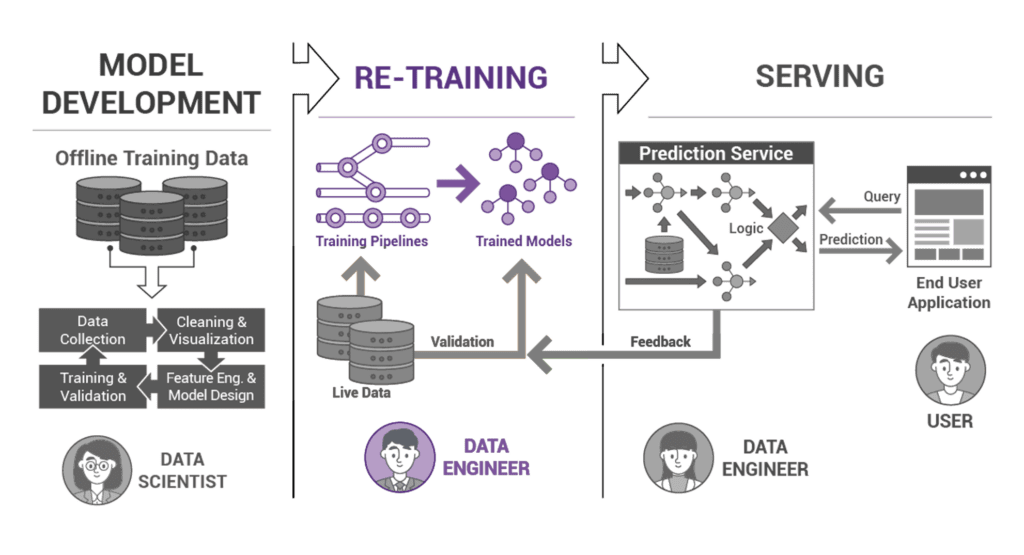
Best Practices in Ensuring the Effectiveness of the Training Layer
The training layer serves as the backbone of the machine learning system, determining how effectively raw data metamorphoses into insightful predictions. To guarantee that this layer operates at its zenith, we must adhere to a set of best practices.
Embracing scalable infrastructure
Scalability is a non-negotiable tenet in today’s rapidly evolving data ecosystem. By deploying the training layer on platforms like Kubernetes or using cloud-based services, you ensure that the infrastructure scales seamlessly with data growth or heightened model intricacy. The payoff? A robust system ready for challenges without incessant manual tweaking.
Regular monitoring and alerts
Stay alert and proactive, not reactive. Continuous monitoring arms you with real-time insights, be it training metrics, system vitality, or resource consumption. The early bird catches the worm, and in this context, it means catching anomalies or hitches swiftly, warranting model consistency and minimal hiccups.
Automated testing
Automation is the future, and testing is no exception. Post-training, having the model undergo a litmus test against a validation set or benchmark dataset guarantees quality adherence. This shield ensures that only models that clear the quality bar move ahead, protecting the downstream processes from sub-par predictions.
Effective checkpoints
Training a model is an investment of time and resources. Why risk losing it all? Periodic model checkpoints during training act as your safety net. Should there be any setbacks, you don’t have to revisit the starting line; instead, pick up from where you left off. The result? An efficient and resource-wise training process.
Optimized data batching
Think of data batching as the rhythm in music. The right rhythm can amplify the melody. Crafting well-optimized data batches can drastically accelerate training. Tools that dynamically adjust batch sizes, considering data intricacies, ensure that hardware accelerators like GPUs/TPUs are used judiciously, striking the right balance between speed and efficiency.
Alignment with business goals
A model’s accuracy isn’t its only success metric. Ensuring the objectives of the training layer resonate with overarching business or application aims is paramount. The ideal scenario? A model that’s not only accurate but also solves tangible business challenges, adding real value to the organization.
Anticipating Challenges in the Training Layer of Machine Learning Systems
As with any technical endeavor, building a robust training layer for machine learning is accompanied by potential pitfalls. While these challenges can be daunting, awareness and preparedness can turn these stumbling blocks into stepping stones.
Data drift
The ever-evolving real world can lead to discrepancies between the training data and actual data the model encounters, known as data drift.
- Imagine a model predicting sales during the year. An unprecedented event, say a pandemic, can cause buying patterns to skew, rendering the model less effective.
Fix: Equip your arsenal with monitoring tools. Upon detecting drift, spring into action by either retraining the model or finetuning it to adapt to the new data landscape.
Resource constraints
Training hungry models on substantial data can strain computational resources if not anticipated.
- Picture attempting to train a behemoth neural network on a standard machine, leading to sluggish training or even crashes.
Fix: Embrace distributed training paradigms or cloud solutions that flex with your resource demands. Concurrently, refining model architectures and streamlining data pipelines can further allay these constraints.
Model overfitting
A model too enamored with its training data, so much so that it learns the noise rather than the pattern, is a classic case of overfitting.
- A boundless decision tree model might ace the training data with perfect accuracy but falter grievously on unseen data.
Fix: Shield your model by employing techniques like cross-validation, regularization, and early stopping. Furthermore, nurturing a diverse and representative training dataset is paramount.
Inconsistent training environments
Differences in software versions, dependencies, or configurations between training environments.
- Imagine a model trained in a development environment with one library version that might behave differently or fail when deployed in a production environment with a different version.
Fix: Use containerization tools like Docker to ensure consistent environments. Also, maintain a documented list of dependencies and versions.
Lack of traceability
Not maintaining proper logs or versioning for models and data.
- For example, after several training iterations and tweaks, you might not remember which model version produced the best results or which dataset it was trained on.
Fix: Use model and data versioning tools like MLflow or DVC. Maintain comprehensive logs of training sessions, metrics, and configurations.
Echo chamber effect
Relying heavily on a feedback loop, especially if the feedback originates from a narrow or non-representative user group, can lead to an “echo chamber” effect.
- The model becomes increasingly tailored to this group’s preferences, reinforcing their biases and potentially making it less accurate or relevant for a broader audience.
Fix: To prevent this increasing bias, it’s essential to periodically re-evaluate the model with diverse datasets and ensure that the feedback being integrated is representative of the broader population or target audience. Techniques like fairness audits, synthetic data generation, or active sampling can be employed to counteract potential biases from feedback loops.
Case Study: The Tale of Jasmine’s Training Layer Adventure
Jasmine, a high school senior, was known for her love of technology. For her final year project, she decided to delve into the world of machine learning. While many of her peers focused on the end results of their models, Jasmine was intrigued by the foundation of it all: the training layer. She embarked on a journey to create the most efficient training layer for her “SongPop Predictor” project.
The training layer is the heart of a machine learning system. It’s where raw data is prepared, processed, and made ready for the model to learn from. Jasmine knew that a well-optimized training layer was crucial for the success of her project.
Jasmine began with a dataset of 100 songs. But what if she wanted to expand to 10,000 songs or even more? She chose cloud-based platforms that could grow with her needs, ensuring that her training layer would always be up to the task.
Instead of manually checking her training layer’s progress now and then, Jasmine set up automated monitoring. This system alerted her if anything seemed off, allowing her to address issues immediately.
Jasmine introduced automated tests within her training layer. Every time new data was added, these tests ensured the data was processed correctly and ready for the model.
Data processing can be time-consuming. Jasmine implemented checkpoints in her training layer. If there were any interruptions, she wouldn’t have to start from scratch; she could resume from the last checkpoint.
Instead of feeding her model all the data at once, Jasmine used data batching. This method processed data in manageable chunks, making the entire process more efficient.
Jasmine’s goal was clear: predict song popularity. She ensured every step in her training layer was aligned with this objective, filtering out any unnecessary data or processes.
Music trends change. Jasmine realized that the data she started with might not always be representative. She had to find ways to continuously update and adapt to new data within her training layer.
As she added more data, Jasmine noticed her computer slowing down. The training layer required more computational power. She overcame this by optimizing her processes and using cloud resources.
While this is typically a concern during model training, Jasmine knew that the root often lay in the training layer. She ensured her data was diverse and representative, reducing the chances of her model getting too attached to the training data.
At the school’s tech showcase, Jasmine’s project stood out. While others showcased their model’s predictions, Jasmine’s presentation focused on the robust training layer behind her model. Her peers were captivated by the unseen hero of machine learning. Jasmine’s project was a testament to the saying, “A strong foundation leads to success.” Through her journey, she not only built a solid training layer but also inspired her classmates to look deeper into the processes behind the results.